For self-service BI to work it needs to be accessible to the many, not just the few.
- 6th September 2016
- Posted by: Plaut Romania
- Category: analytics

Mathematics and statistics are (thankfully) devoid of many of the idiosyncrasies of human language. As you’ll often hear, there’s a purity in the numbers. But numeracy and data literacy vary widely, both in society and within our organizations. For many of us, the spoken and written word is still how we best understand information. It’s the descriptive power that turns cold, hard data facts into meaningful messages that people can communicate and act upon. And that takes skill. You need to be able to ‘read’ the data, (or visualizations) and then articulate what they are ‘telling’ you. That’s what makes a great analyst—not just discovering the insight but also communicating the abstract in an understandable way.
As we know, data visualization is a powerful medium for both revealing and communicating data facts. Unfortunately it relies heavily on the viewers ability to read, process and understand what they are looking at. Much of the problem with the lagging adoption of analytic practices is that the tools and data artifacts are rarely designed to help people in that endeavor. At best it’s designed for the trained analyst, which is great, if you’re a trained analyst. But data-driven decisions need to be made by a wide variety of people with varying skills. For ‘self-service’ BI to work it needs to be accessible to the many, not just the few. That’s where artificial intelligence and natural language generation (NLG) can help out. NLG in this scenario, is the ability to automatically communicate analytical observations in clear, understandable language.
The guidance that NLG brings to a data visualizations, is in the form of a descriptive layer and can be extremely useful for building data literacy. If we consider D’Ignazio and Bhargava’s 4 principles of designing for data literacy; it can supply focus for the reader by highlighting the data facts of importance. It can guide the reader by surfacing the sort of insights that can be drawn from the data visualization. It’s inviting because it uses terms and phrases the reader understands and it’s expandable because it can help introduce advanced and very sophisticated visualizations in a way that helps people to learn how to read them. Of course the impact and usefulness of NLG goes far beyond improving data literacy. It can support a wide range of ideas for creating people-centric data experiences.
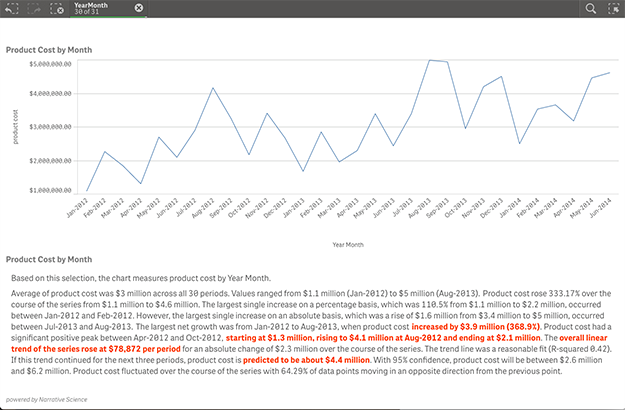
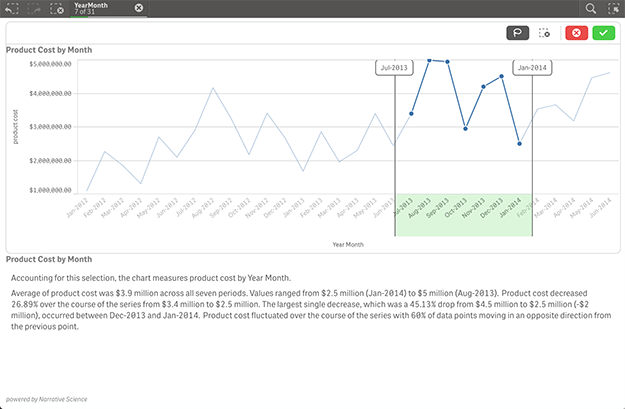
All this fits nicely into how we approach designing for analytics at Qlik. The Innovation and Design group has been busy for a while now exploring the benefits of NLG and creating people-centric ways to analyze and work with data. Qlik was the first BI company to debut NLG as part of an integrated and interactive dashboard, through our partnership with Narrative Science.
Our partnerships with Narrative Science and YSEOP Savvy over the past year have led to intuitive and powerful natural language extensions that can be used to add narratives to data visualizations in Qlik Sense apps. Best of all they are tied to Qlik’s associative model so that they rewrite their narratives instantly the moment you make a selection, asking a new question.
Our journey with natural language started with the early work on the search capabilities in Qlik Sense. The latest release of Qlik Sense demonstrates how we are moving ever closer to naturally interacting with our data, creating a genuine dialogue between us and the data. And that immediacy and fluidity makes all the difference when it comes to getting the best insights for decision making. After all, a conversation beats a monologue every time.
Links to demos and assets
Great example on Qlik Branch of using the QIX engine for search –http://branch.qlik.com/#!/project/56af9cc5126a633074bea476
And finally, a great overview of what it takes for machines to generate natural language here’s a webinar by Kris Hammond from Narrative Science on the Artificial Intelligence ecosystem https://vimeo.com/167156248